AWS 시스템 운영
모니터링 체크리스트 항목
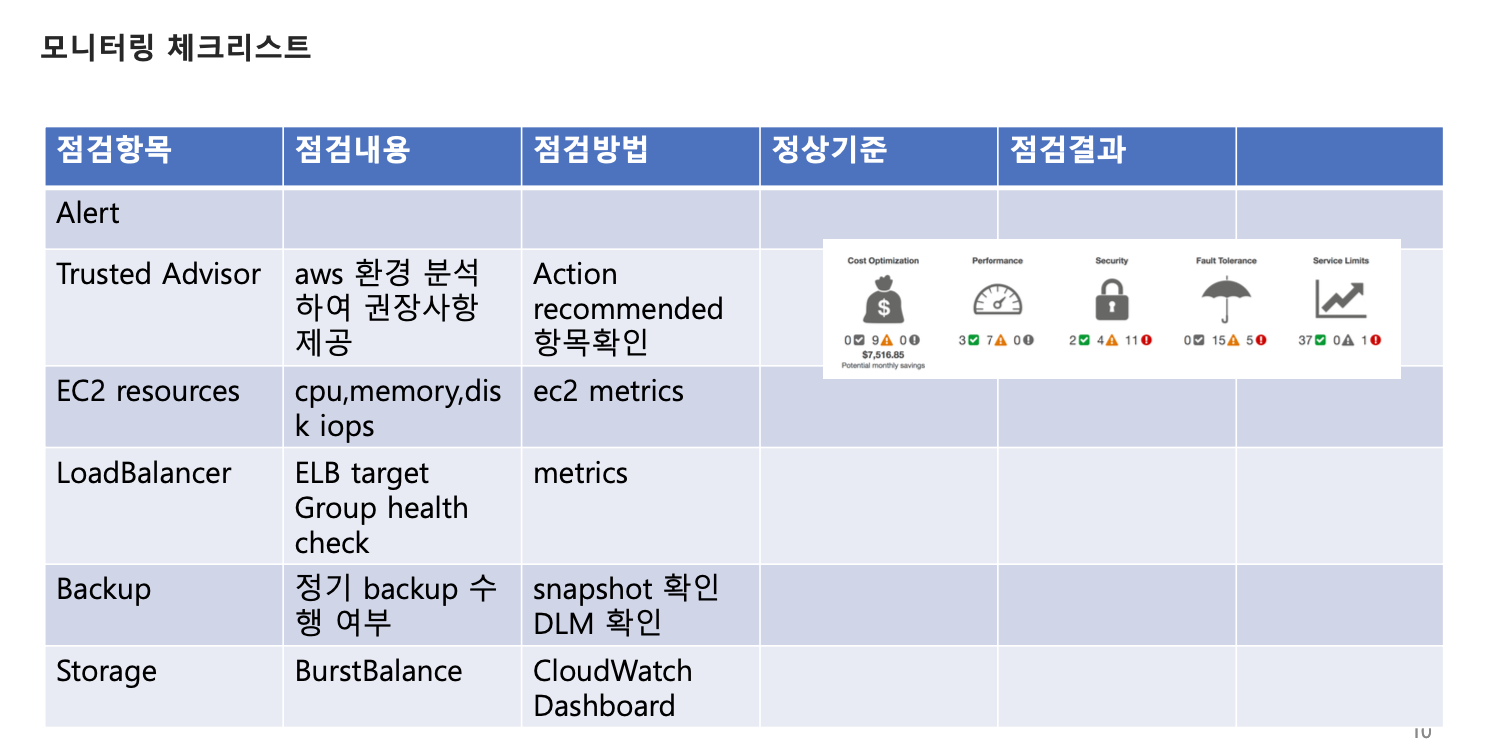
BurstBalance
- iops(Input Output Per Second)란? - 저장 장치의 초당 입출력 처리량
- BurstBalance란?
- IOPS가 정해진 기준을 초과하면 서비스 불가능한 수준으로 IOPS 낮춤
- But, 예측하지 못한 IOPS에 대비하기 위해 BurstBalance 존재
- 사용량이 적을때는 사용하지 않는 IOPS를 저축하고 있다가 IOPS가 급증할 때 저축했던 IOPS사용하는 개념 → Burst Balance credit
- Burst balance는 최대값(gp2 기준 3000)이 있기 때문에 burst balance가 0이되면 성능 지연(서비스 불가수준) → 모니터링을 통해 gp2 용량을 늘리거나 볼륨 타입을 io1으로 바꿔 대응 필요
- 참고

백업 복구 정책(EC2- lifeCycleManager(volume backup), AMI 등)
- 참조링크
- https://dev.classmethod.jp/articles/ec2-instance-backup-by-amazon-dlm/
- https://aws.amazon.com/ko/premiumsupport/knowledge-center/ebs-snapshot-data-lifecycle-manager/
- AMI, 볼륨 Snapshot 모두 비용발생하므로 적절한 보관 주기 설정 필수
- AMI(Amazon Machine Image) : EC2에 연결되어 있는 OS가 설치 되어있는 루트 장치를 포함한 모든 EBS를 백업하는 것
- AMI를 생성할 땐 no reboot 옵션 체크
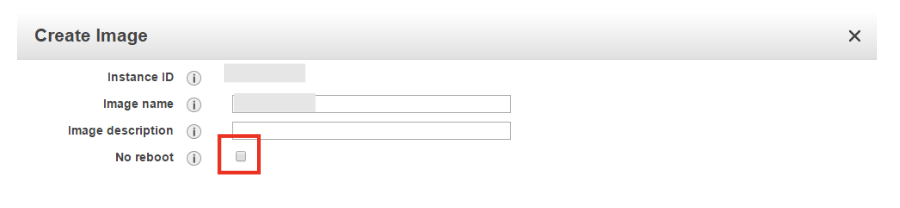
- Snapshot : 볼륨 백업
- AMI에 포함된 Volume snapshot 자동 생성되어 보관됨 > 볼륨 스냅샷만 지우려해도 삭제 불가, AMI 삭제> 볼륨 스냅샷 삭제 순으로 진행
- 시스템 성격별(상용,검수,개발), 자원별(EC2, RDS, ElastiCache 등) 적절한 보관주기와 백업 주기 필요
AWS Native 서비스를 이용한 모니터링(CloudWatch Dashboard 구성, CloudTrail, Config, vpc flowlogs 등)
CloudWatch (대시보드 구성)
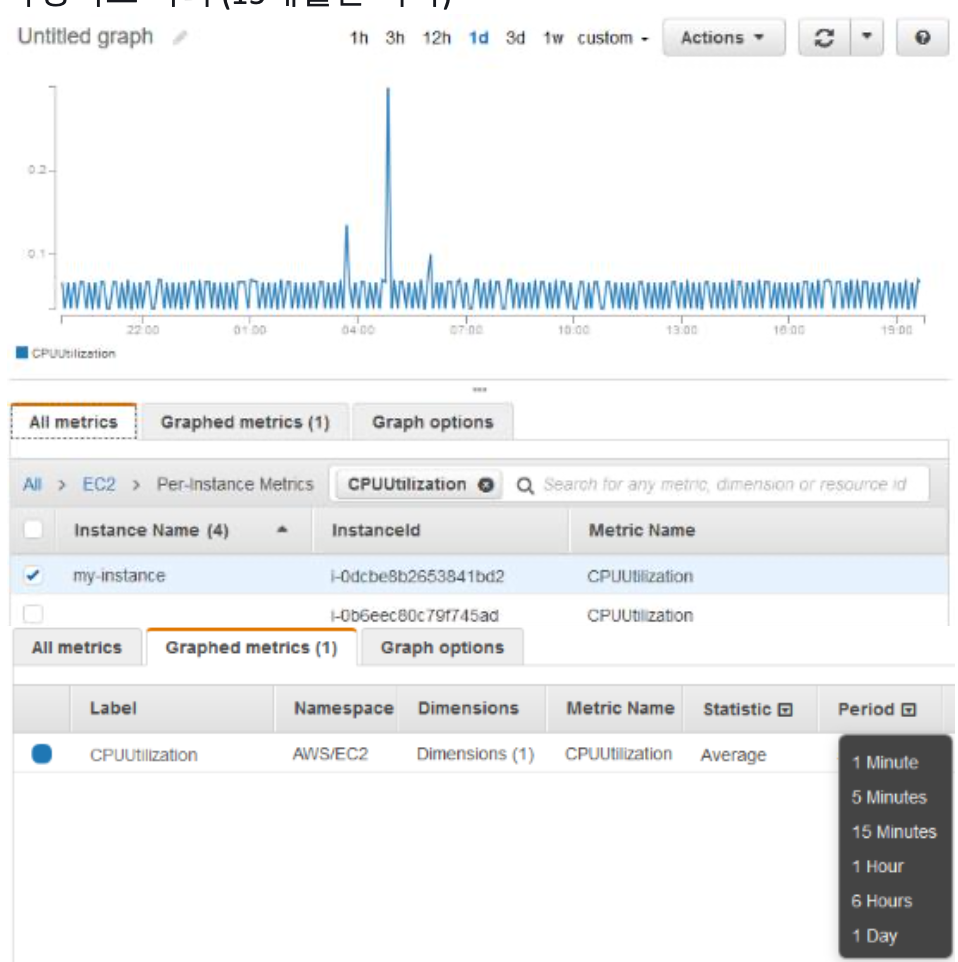
- Amazon EC2에서 원시 데이터를 수집하여 읽기 가능하며 실시간에 가까운 측정치로 처리 (15개월간 기록)
- Amazon EC2는 기본적으로 측정치 데이터를 5분 동안 CloudWatch에 전송
- Amazon CloudWatch의 원시 데이터를 기초로 하는 일련의 그래프가 표시
- 그래프 대신에 Amazon CloudWatch에서 인스턴스 데이터를 얻을 수 있음
- 탐색창에서 지표 선택
- EC2 측정치 네임스페이스 선택
- 인스턴스별 지표 차원 선택
- 검색필드에 원하는 지표 검색 후 특정 인스턴스행 선택
- 연필아이콘 - 그래프 이름 지정/시간범위 변경 혹은 사용자지정
- 측정치에 대한 통계 또는 기간 변경 시 Graphed metrics > Period
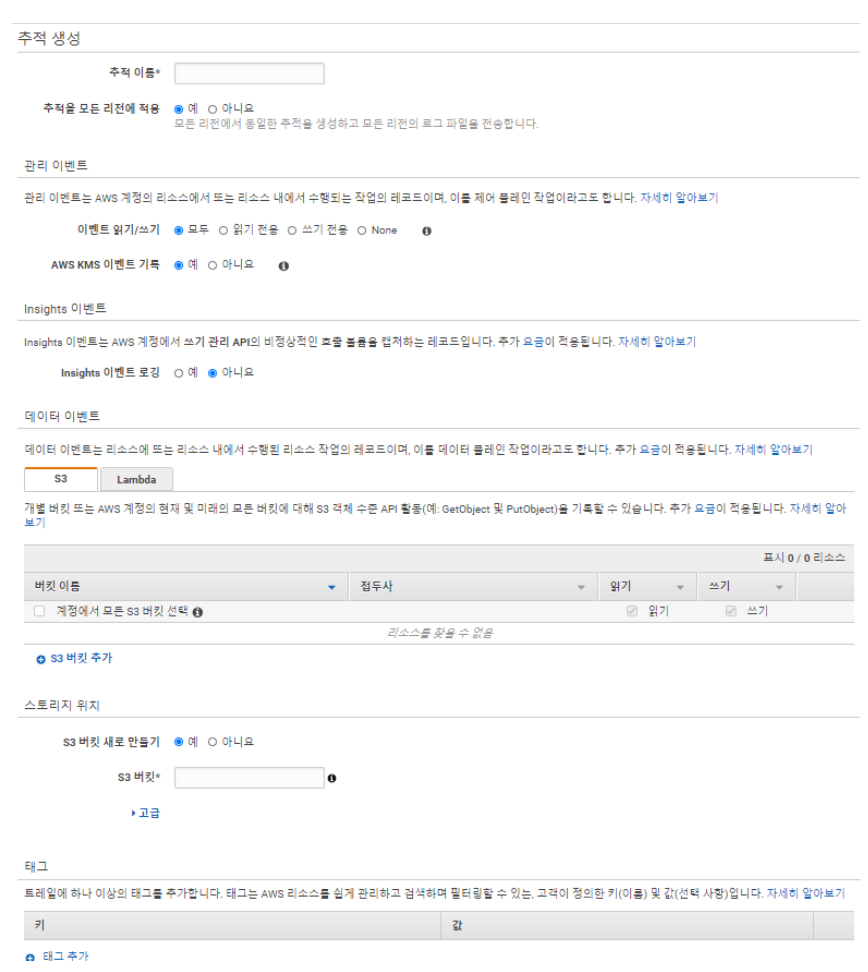
CloudTrail(IAM 계정별 작업 로그)
- 각 리전에 대해 최대 5개의 추적생성 가능
- 추적을 생성하면 CloudTrail은 사용자가 지정한 이벤트에 대한 로깅을 자동으로 시작
- 로깅을 중지하려는 경우 추적에 대해 로깅을 해제하거나 추적 삭제
- 추적을 생성하고자 하는 AWS 리전 선택
- Get Started Now > Trail name 추적 이름 입력
- Apply trail to all regions : yes (기본값) / no (추적 생성 리전에서만 파일 로깅)
- 관리 이벤트 설정 (Log AWS KMS events : yes (기본값) / no (이벤트 필터링 시)
- Log Insights event : yes (트레일에서 인사이트 이벤트 로깅 시)
- Data events – S3 버킷, Lambda 데이터 이벤트 로깅 지정 가능 (추가요금 부가)
- Storage location > Create a S3 bucket : yes > 버킷 정책 생성 및 적용
Config
- AWS리소스의 인벤토리와 해당 리소스에 대한 구성변경 기록 제공
- AWS 리소스 구성이 원하는 설정인지 평가
- AWS 계정과 연결된 지원되는 리소스의 현재 구성을 스냅샷으로 만듦
- 계정에 있는 하나 이상의 리소스의 구성과 기록구성 검색
- 리소스가 생성, 수정 또는 삭제될 때마다 알림
- 기록할 리소스 유형 지정(모든 리소스 / 특정유형)
- AWS Config가 구성기록 및 구성스냅샷 파일을 보낼 S3 버킷선택
- Amazon SNS 주제 > 구성 변경 사항과 알림을 Amazon SNS 주제에 스트리밍합니다. : 체크하기
- AWS Config 역할 > 구성 정보기록과 보낼 수 있는 권한 : IAM 역할선택
- 규칙 하나 이상 선택

- A) AWS Config가 기록 중인 리소스의 총 개수
- B) 리소스 유형을 내림차순 확인 / 유형 선택 > 리소 스 인벤토리
- C) 모든 리소스 보기 > 리소스 인벤토리
- D) 미준수 규칙 개수
- E) 미준수 리소스 개수
- F) 상위 미준수 규칙 내림차순
- G) 모든 미준수 규칙 보기 > 규칙 페이지
VPC flowlogs
- 네트워크 모니터링에서 로그 수집 기능 향상
- VPC 서브넷과 ENI의 네트워크 트래픽이 저장
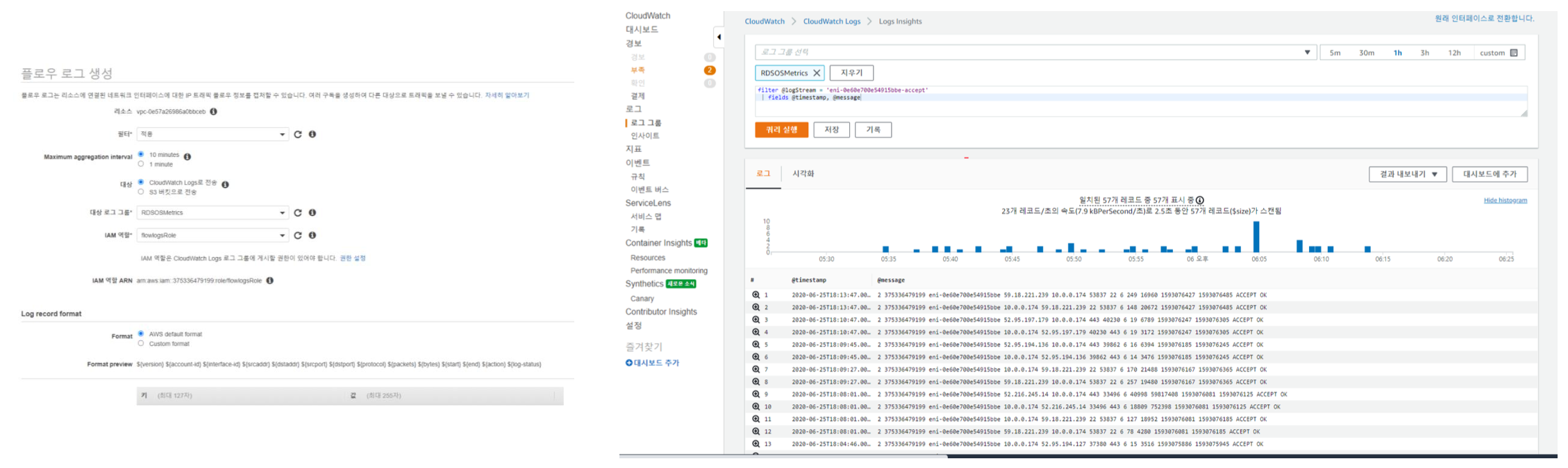
AWS Native Monitoring service 특징
- CloudWatch - cpu, memory, disk iops, network, health check 등 대시보드, Policy 설정하여 알람 기준 설정
- CloudWatch Logs Insights
- vpc flow logs, cloud trail 등 다양한 로그는 범위가 방대하고 크기가 커서 분석이 어려움
- 쿼리 기반으로 필터링 및 로그 분석 기능 제공 + 시각화하여 대시보드에 등록
- 스캔한 로그 데이터 크기에 비례하여 요금 증가
- 참고
- 참고
서드파티 모니터링 솔루션 제안(Whatap kube(상용 서비스), Grafana+Prometheus 자체 구축, data dog 등)
Zabbix - Zabbix
- 엔터프라이즈급 오픈소스 분산 모니터링 솔루션 (Zabbix + Grafana)
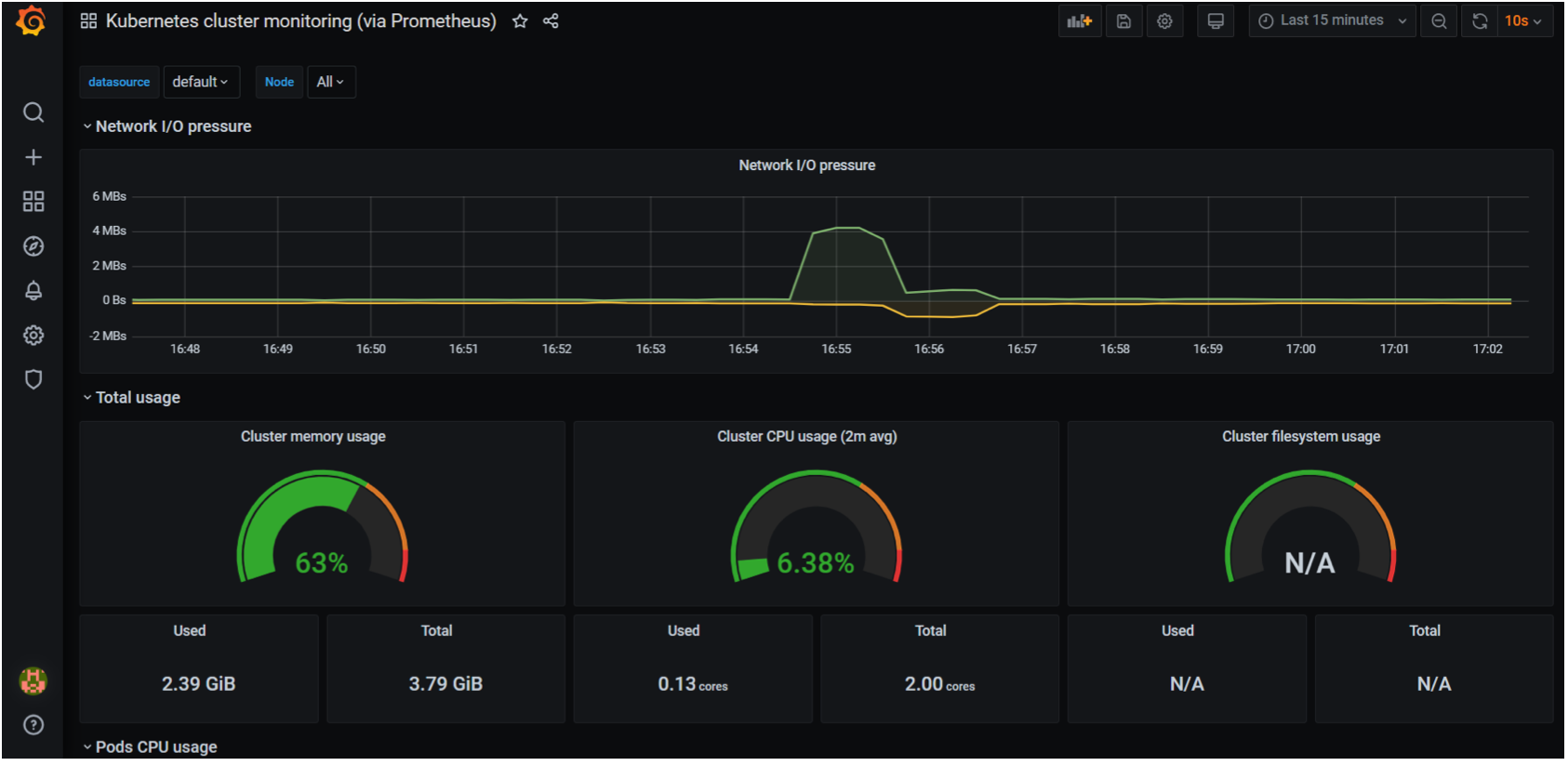
Prometheus + Grafana
- Grafana + Promethus(컨테이너 모니터링 최적화) : 파드 러닝, 스탑/ 노드 cpu, memory, disk iops, network, health check/ pod별 memory, cpu 등 지표 포함
Whatap
data dog
AWS 운영 팁
- Tag
- Name, Environment(상용, 개발, 검수), Project, Service 필수 지정
- 리소스 정리(필터링을 통해 자원 정리), 비용 할당(태그로 Billing Report에서 비용 분류), 자동화(DLM 적용, 서버 자동기동, 중지), 액세스 제어(태그 값에 따라 IAM 권한 제한) 등에 사용
- Switch Role
- 여러 계정을 사용할 때, 별도 인증 절차 없이 Switch Role 설정을 통해 A계정에서 B계정으로 전환 가능
- Lambda 사용
- 운영 자동화(서버 자동 기동/중지)
- EC2 Health Check 중 이상 알람
ETC
Link